성능 데이터 모델링
개요
데이터베이스의 성능 향상을 목적으로 가하는 각종 설정, 구조화.
이것은 언제든 할 수 있는 것이지만, 분석 설계 단계에서 할 때 비용이 가장 적게 들어간다.
특히 운영 단계에서 모델링을 수행하는 것은 많은 비용이 들어가므로 미리 성능에 대한 고려를 할 필요가 있다.
고려사항
다음의 고려사항들이 있다.
이러한 순서를 거친다.
데이터 구조에 따른 성능
데이터 구조가 어떻냐는 성능에 큰 영향을 끼친다.
이를 위해 기본적으로 정규화를 진행한다.
그러나 이러한 정규화가 오히려 성능에 악영향을 끼치는 경우도 존재하며, 그렇기에 반정규화를 하기도 한다.
대량 데이터에 따른 성능
테이블에 너무 많은 데이터가 많은 상황.
그 테이블에 트랜잭션이 많이 발생한다면..
이럴 때는 테이블을 수직, 수평 분리하는 방법이 유효하다.
이럴 때는 디스크 I/O 자체를 감소시키는 것이 효과적이라는 것이다.
조인이나, 집계 함수처럼 연산이 필요한 케이스가 아니라 단순히 읽거나 쓰는 값이 많은 것 자체가 문제이기 때문.
테이블 내의 모든 행은 블록 단위로 디스크에 저장된다.
보통 이 블록은 8kb(처음 디비 세팅할 때 설정할 수 있다).
칼럼이 많아지면 하나의 행을 저장할 때 물리적으로 여러 블록에 걸쳐 저장하게 된다.
그런 경우가 얼마나 되겠냐마는 한 행이 8193바이트라면 두 블록을 읽는데 불필요한 8191바이트는 그냥 버려진다.
즉, 하나의 행을 읽는데 여러 블록을 거쳐야 하고, 그러면 성능 저하가 발생하게 된다.
8kb의 단위가 잘 감이 안 오니 생각해보자.
우리가 흔히 정수형 타입으로 사용하는 int는 4바이트이다.
1키로 바이트는 2의 10승이니, int가 256개 있다고 보면 되겠다.
그렇다면 8kb는 int가 2048개 있는 크기이다.
아스키 코드 글자로는 8196개, 대충 글씨 많은 한 문서 크기 정도되는 것이다.
성능 저하 현상
구체적으로 다음의 두 가지 방식으로 성능 저하가 일어난다.
로우 체이닝(Row Chaining)
한 행 길이가 너무 길어서 두 블록에 걸쳐 데이터가 저장된 경우이다.
위의 예시에서 든 케이스이다.
로우 마이그레이션(Row Migration)
데이터 블록에 수정이 발생할 때 생기는 현상이다.
원래는 한 블록에 행이 다 담겼는데, 행 크기가 변경된다면?
그러면 새로운 블록에 데이터를 옮기는 마이그레이션이 발생한다.
이때 원래 블록에는 새 블록이 어딘지만 참조만 남긴다.
그러면 이제는 데이터를 읽을 때 블록을 읽고 읽어야 하는 상황이 된다..
테이블을 처음 만들 때 대부분 크기를 지정한다.
그럼 왜 마이그레이션이 발생할까?
일단 가변형 데이터 타입, TEXT, VARCHAR 등이 있으면 발생할 가능성이 생기게 된다.
또 NULL로 시작한 컬럼에 데이터를 추가할 때도 이런 현상이 발생할 수 있다.
오라클에서는 PCTFREE, PCTUSED라고 하여 블록 여유 공간을 설정하는 식으로 이걸 줄인다.
그럼에도 이걸 넘기면 얄짤 없이 마이그레이션이 발생한다.
블록 I/O의 문제는 그 자체로도 비효율이지만 곧 디스크 I/O의 문제로 이어진다.
디스크를 읽는 작업은 엄청난 성능 이슈를 발생시키게 된다!
가능한 방법
무조건 디스크쪽으로 이슈가 이어지는 건 아니다.
다음의 경우로 디스크에 가지 않고 메모리 선에서 작업을 해결하는 경우도 있다.
- 디비 캐싱
- 한번 조회된 블록은 그래도 메모리에 잠시 캐싱된다.
- 비동기적인 쓰기
- 트랜잭션이 커밋되거나, 특정 시점이 돼야 실제 디스크에 업데이트를 반영한다.
- 연속적 블록 읽기
- 데이터가 순차 저장됐다면 한번 블록을 읽을 때 한꺼번에 읽는다.
- 병렬 처리, I/O 스케줄링
- 최신 디스크 시스템은 병렬 처리가 된다.
- NVMe, SSD는 이에 특화됐다.
- 프리페칭
- 예상되는 데이터 요청에 따라 미리 블록을 읽어오는 작업을 하기도 한다.
이러한 방법들을 통해 디스크 I/O로 인한 성능 저하를 어느 정도 해결할 수 있다.
데이터베이스 구조에 따른 성능
데이터의 구조 말고도, 데이터베이스의 구조 역시 성능에 영향을 미친다.
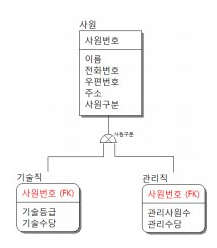
위에서 이야기한 슈퍼/서브 타입 모델이 여기에서 나온다.
공통되는 부분은 슈퍼 타입 엔터티로 꺼내고, 이걸 상속받아 서브 타입 엔터티를 만드는 방식이 바로 슈퍼/서브 방식이다.
이 작업은 논리적 데이터 모델링 때 이뤄진다.
실제 물리적 데이터 모델링으로 넘어갈 때 어떻게 할 지는 설계자 자유다.
각각이 장단점이 있어 고려할 필요는 있다.
All in One
그냥 저런 구분 없이 한 테이블에 꼬라박는 방식이다.
이건 모든 데이터에 대한 트랜잭션이 빈번하다면 유용할 수 있다.
업데이트를 위해 매번 union하는 것보다는 나을 수 있다는 것.
아래 방식보다는 I/O 성능과 확장성은 나쁘다.
Plus
테이블 분리는 하는데, 상위 타입은 안 두는 식이다.
당연히 칼럼 자체는 중복되게 된다.
데이터 처리가 분리된 기준으로 된다면, 유용하다.
One To One
위처럼 슈퍼와 서브를 확실히 나누는 방식이다.
슈퍼 타입쪽에서 변경이 없고 서브 타입에 대한 변경만 많이 일어난다면 유용하다.
분산 데이터베이스에 따른 성능
데이터가 엄청 많아질 때 흔히 사용하는 선택지는 분산화이다.
데이터베이스 역시 분산화하여 하나로 묶어 사용하는 경우가 있다.
이것이 바로 분산 디비..
장점과 단점을 리스트로 정리해보자.
- 장점
- 지역 자치성, 점증적 시스템 용량 확장
- 신뢰성, 가용성
- 효용성, 융통성
- 빠른 응답 속도와 통신 비용 절감
- 왜 통신 비용이 절감되냐?
- 사용자의 위치에 가까운 디비가 반응
- 트래픽이 다중 노드에 분산
- 데이터의 가용성, 신뢰성 증가
- 시스템 규모의 적절한 조절
- 각 지역 사용자의 요구 수용 증대
- 단점
- 소프트웨어 개발 비용
- 오류 잠재성 증가
- 처리 비용 증가
- 설계 및 관리 복잡성과 비용
- 불규칙한 응답속도
- 통제 어려움
- 데이터 무결성 위협
투명성(Transparency)
여기에서 투명성이란 개념이 성립한다.
분산 데이터베이스를 사용자는 분산된 것을 인식하지 못하고 사용할 수 있게 하는 속성이다.
다음의 종류가 있다.
- 분할 투명성(단편화)
- 하나의 논리적 테이블이 여러 개로 단편 분할되어 사본이 여러 곳에 저장
- 사용자는 한 곳에 위치하는 것으로 인식해야 충족됨
- 위치 투명성
- 사용하려는 데이터 저장소를 명시할 필요없어야 충족
- 위치 정보는 시스템 catalog에서 알아서 유지돼야 한다.
- 지역 사상 투명성
- 지역 DBMS와 물리 DB 사이의 매핑이 보장됨
- 그래서 지역과 관련 없이 활용할 수 있다.
- 중복 투명성
- 데이터가 어떻게 얼마나 중복됐는지 사용자는 모름
- 장애 투명성
- 구성요소의 장애에 무관하게 트랜잭션의 원자성을 유지한다.
- 한 노드가 죽어도 잘 돼야 한다는 것이다.
- 병행 투명성
- 다수의 트랜잭션이 동시에 수행돼도 결과의 일관성이 보장돼야 한다.
- 여기에는 locking, timestamp 방법이 사용된다.
분산 디비는 참 어렵다..
내가 봤을 때 장애 투명성은 흔히 엔지니어가 고려하는 사항이다.
그리고 병행 투명성은 개발자가 고려한다.
이건 싸피를 나온지 얼마 안된 24년도의 내가 생각하는 방향인데, 정확하진 않다.
진짜 DBA의 생각을 들어봐야 알겠지.
적용 기법
분산 디비에는 다양한 방법이 있다.
테이블 위치 분산
테이블을 각각 다르게 위치시키기.
이럴 거면 왜 쓰냐?
잘 모르겠다.
테이블 분할 분산
말 그대로 테이블을 쪼갠다.
수평, 수직 방식이 있다.
테이블 복제 분산
동일한 테이블을 다른 지역이나 서버에 동시에 생성한다.
여기에는 두 가지 방식이 있다.
부분복제는 통합 테이블을 한군데에서 관리하고, 다른 곳은 일부만 가진다.
광역복제는 진짜 모두가 다 가진다.
테이블 요약 분산
노드 간 데이터가 비슷하긴 하지만 다른 유형으로 존재.
각 노드의 요약 정보를 메인에서 통합 분석하거나, 각 노드의 정보를 메인에서 요약해서 분석하거나.